New Publication: Creating Specialised Corpora from Digitized Historical Newspaper Archives
Notice of new publication in Digital Scholarship in the Humanities.
One of the promises of digital humanities for the ‘historical sciences’ is that we’ll be able to, in Tim Hitchcock’s words, shift from ‘piles of books’ to ‘maps of meaning’. That is, we’ll be able to produce high level representations of phenomena across large collections of text. These could come in all sorts of forms. But, for a concrete example, consider the following:
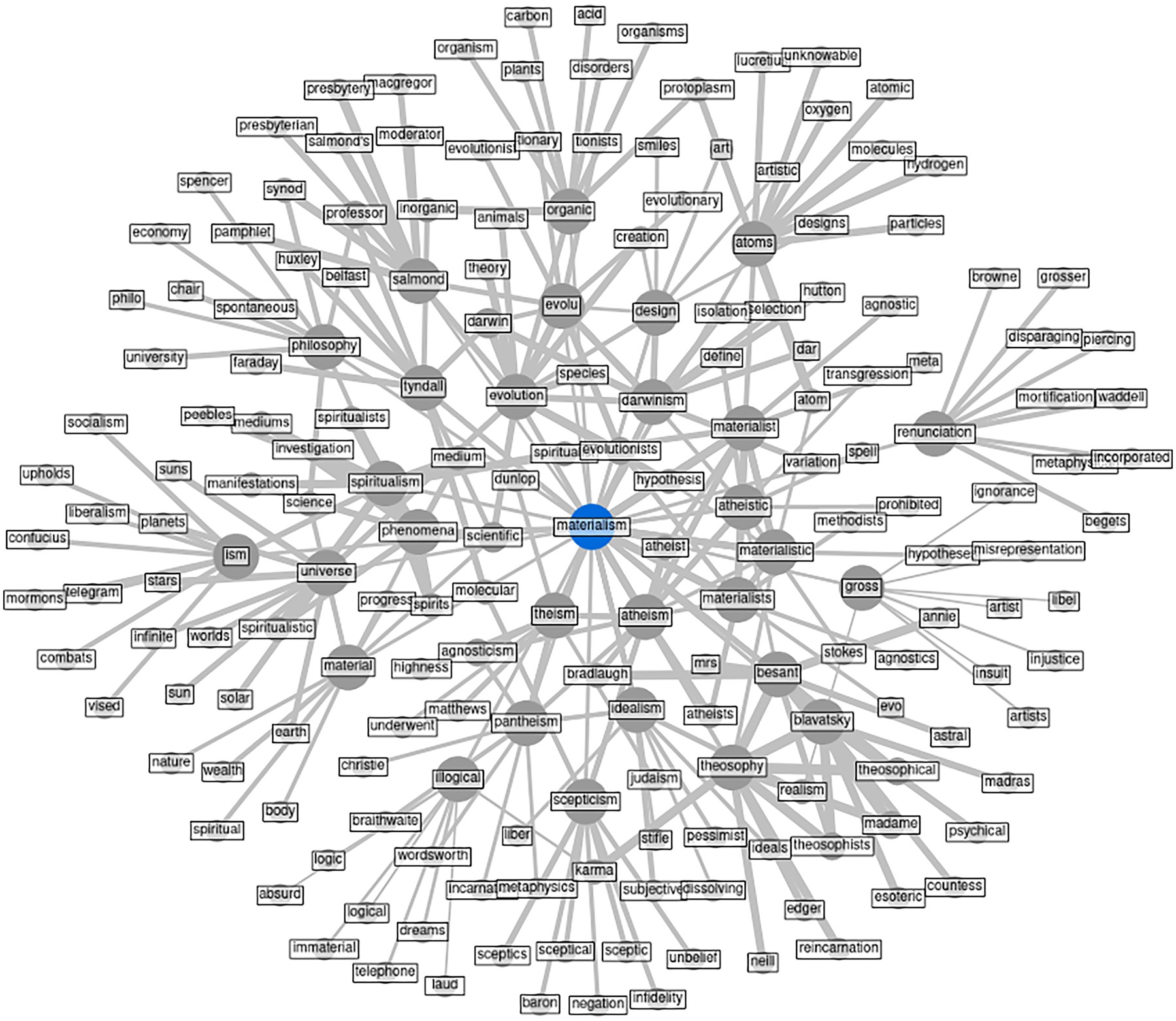
This is a ‘cooccurence network’ for the term ‘materialism’ as it appears in a corpus of pre-1900 newspaper items from New Zealand. It depicts terms which a connected to ‘materialism’ in a statistically surprising way and terms which are similarly surprisingly connected to those terms. Networks of this sort can both motivate specific research questions and provide a depiction of the wider context for the use of a given term. More such networks can be produced here. The same link provides an explanation of the meaning of these connections.
When confronted with a huge collections of digitised material, it is very hard for an individual researcher or small team of researchers with interests in a specialised topic and limited computational researchers to apply contemporary text mining and other computational methods. With 1000s of GPUs and 1000s of hours to run them (not to mention the gas to burn), you can create a highly general representation of what is going on in a collection of texts and then query it about specific topics. This is one way of thinking about what ChatGPT etc are: interactive general representations of phenomena in this or that large-scale collection of texts (rather than ‘intelligence’ in any sense I’d consider meaningful). We thus need methods for selecting items for inclusion in corpora. Moreover, for reasons described in the paper, we want methods which do not rely on simple keyword searches.
My contribution to this problem has just been published with open access in Digital Scholarship in the Humanities. The paper is called “Creating specialized corpora from digitized historical newspaper archives: An iterative bootstrapping approach”. It provides a methodological motivation for applying text mining techniques to historical datasets and sets up the need for methods to select subsets of these datasets for analysis. It then provides a general approach to producing corpora for analysis from large historical newspaper collections along with Python code for each stage of the process.
The core idea of the method is that the text mining methods which we want to apply to gain insight into a specialised topic can also be used to generate increasingly focused corpora. We start with some initial candidate corpus, and apply methods such as cooccurrence network analysis or topic modelling, in order to find material which is either relevant or not relevant to our topic. We label the material and then train naive Bayes classifiers, which are then applied to the full newspaper dataset to generate a new candidate corpus. That is, we work upwards from an inappropriate corpus of items (inappropriate by including lots of irrelevant material and/or excluding relevant material). As we iterate this process, the corpus becomes increasingly targeted. I illustrate the method by generating a corpus of philosophical discourse in pre-1900 English-language New Zealand newspaper data made available by the National Library of New Zealand.
I’m a bit slow in making a noise about this publication. It came out as I was in the hospital for the birth of my first child, Clement. Clem and his mum are doing very well. I am now returning to work now after my parental leave.
I should also say that in the proofing phase I missed the fact that my sectioning was flattened to a single level! Perhaps this was (pre-)baby brain.
What are the next steps? This paper came out of a summer project towards my data science qualification. As such, it very much focuses on the general methodological problem outlined above. I am currently working on a paper in the history of philosophy which actually uses the corpus I report on in this paper. The basic idea is to focus attention use the newspaper controversy generated by William Salmond’s pamphlet The Reign of Grace (see Wood, 2014). Salmond argues, against then overwhelmingly dominant forms of Christianity, that human beings can be saved after they die. A combination of traditional close reading and the use of cooccurrence networks will be used to reveal deep connections between the theological questions of heaven and hell and the live political questions about nature and purpose of punishment. But this is another story.
